
“Do You Smile in Your Dreams?”
Timothy Gmeiner - Director & Composer // Mingyong Cheng - Visual Designer, Creative Contributor // Nathaniel Haering - Sound-Design & Spatialization
“I've been told a person with late-stage dementia probably doesn't even know I'm in the room, let alone interacting with them. But that would never stop me from talking. You could argue it was a mirage, but every once in a blue moon I'd see their eyes light up, if just for a spec of a moment; like windows they struggled to reach and touch to let me know they were still inside. I like to think that was the moment my words or voice pushed through, if even just to populate their dreams with a familiar tone.”
Artist Statement: Underneath the deepest of pain we often find an even deeper beauty that only exists because of the stakes it was developed under. Our connections to each other, forged through singular and collective memory, are what inspires us to brave through this pain in hopes of experiencing that bittersweet beauty.
Abstract: "Do You Smile In Your Dreams?" is a spatialized fixed media audiovisual installation that journeys through a mind with dementia to paint the walls with sound: music and words that poke through the fog and isolation to invite brief moments of colorful memory and human connection.






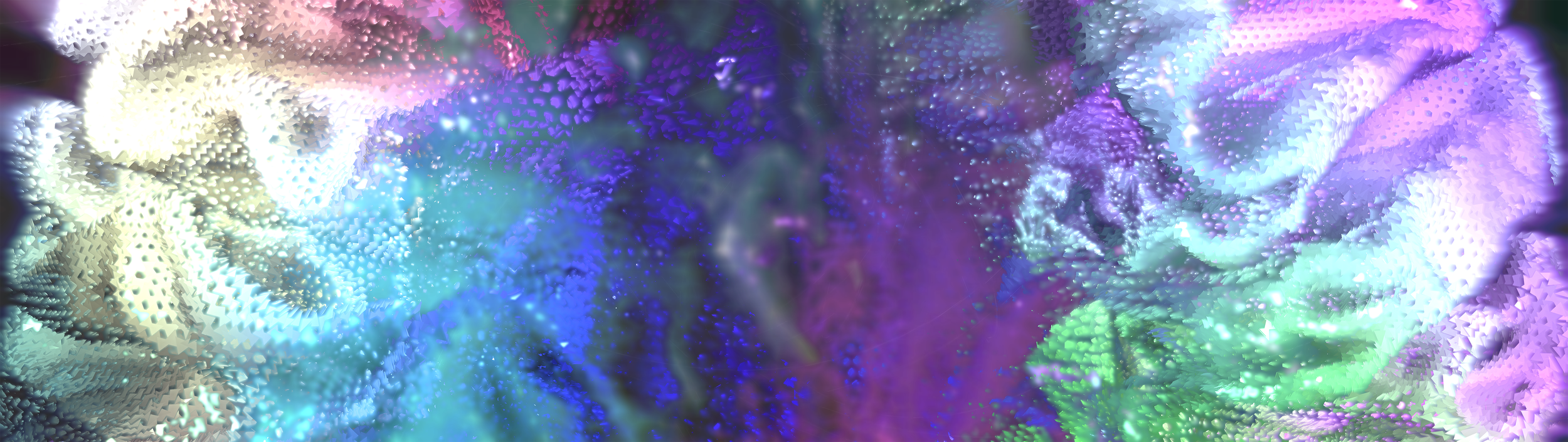





Narrative: In this story, indistinguishable murmurs from strangers in a hospital room heard by the patient are interrupted by a loved one's voice which cuts through the fog and confusion. This voice, presented in the piece as a Cherokee recitation of “The Lord’s Prayer”, provides the basic for recollection, represented by colorful reactivity in the patient's 3D MRI brain scan every time it’s heard. These brief moments of connection end with the patient's successful retrieval of a series of meaningful memories.
Visual: Our visual design integrates open-source MRI videos and 3D brain-scanning models with a computational visual system, remapping the scientific data with artistic expression. A.I., viewed as a representation of our collective memory, gathers text-based inspiration and elements through an A.I. chatbot to co-create this piece’s visual elements.
Audio: This piece is founded on a fixed media composition formed to the narrative arc of emergent memory. Sonic cues are interwoven with musical elements. Specifically, a Cherokee rendition of “The Lord’s Prayer" is split into clips and used as source audio to trigger visual activity in the 3D brain-scan models. Real-time, spatialized, granular synthesis and exponential, filtered delays stochastically disperse manipulated fragments of voices throughout the listening/internal mind space to simulate neurons firing electrical impulses and synapses reaching out and attempting to form connections as memories begin to break through the enveloping mental fog; moving from obfuscation to clarity and back again as the sounds strike upon core memories and elicit the powerful myriad of emotions bound to them.




Audiovisual Reactivity: Visual properties of our brain-scanning models react to the amplitude of specific audio elements within the piece. An earlier iteration of this piece allows for real-time reactivity such that a trained model of an ongoing MRI scan sequence triggers the launch of an audio clip which in turn triggers a visual distortion of the MRI, indicating reception of an audio message. This real-time reactivity is an optional approach for presentation of our current iteration.

Presentation: This piece was presented in February 2023 in the Qualcomm Institute’s Calit2 Theater at UC-San Diego on a tile-displayed set of 32 55” screens with 7.1 multichannel audio.
Sources:
3D Brain-scan models: Edlow, Brian L. et al. (2019), Data from: 7 Tesla MRI of the ex vivo human brain at 100 micron resolution, Dryad, Dataset, https://doi.org/10.5061/dryad.119f80q
“The Lord’s Prayer” in Cherokee (author unknown): https://youtu.be/RnMluQy4EmA
Acknowledgements: UC-San Diego via the IDEAS Initiative and Crossing Boundaries program